Построить матрицу парных коэффициентов корреляции в excel. Матрица парных коэффициентов корреляции
Коллинеарными являются факторы …
И коллинеарны.
4. В модели множественной регрессии определитель матрицы парных коэффициентов корреляции между факторами , и близок к нулю. Это означает, что факторы , и … мультиколлинеарность факторов.
5. Для эконометрической модели линейного уравнения множественной регрессии вида построена матрица парных коэффициентов линейной корреляции (y – зависимая переменная; х (1) , х (2) , х (3) , x (4) – независимые переменные):

Коллинеарными (тесно связанными) независимыми (объясняющими) переменными не являются
…x (2)
и x (3)
1. Дана таблица исходных данных для построения эконометрической регрессионной модели:
 Фиктивными переменными не являются
…
Фиктивными переменными не являются
…
стаж работы
производительность труда
2. При исследовании зависимости потребления мяса от уровня дохода и пола потребителя можно рекомендовать …
использовать фиктивную переменную – пол потребителя
разделить совокупность на две: для потребителей женского пола и для потребителей мужского пола
3. Изучается зависимость цены квартиры (у
) от ее жилой площади (х
) и типа дома. В модель включены фиктивные переменные, отражающие рассматриваемые типы домов: монолитный, панельный, кирпичный. Получено уравнение регрессии: ,
где  ,
, 
Частными уравнениями регрессии для кирпичного и монолитного являются …
для типа дома кирпичный ![]()
для типа дома монолитный ![]()
4. При анализе промышленных предприятий в трех регионах (Республика Марий Эл, Республика Чувашия, Республика Татарстан) были построены три частных уравнения регрессии:
![]() для Республики Марий Эл;
для Республики Марий Эл;
![]() для Республики Чувашия;
для Республики Чувашия;
![]() для Республики Татарстан.
для Республики Татарстан.
Укажите вид фиктивных переменных и уравнение с фиктивными переменными, обобщающее три частных уравнения регрессии.
5. В эконометрике фиктивной переменной принято считать …
переменную, принимающую значения 0 и 1
описывающую количественным образом качественный признак
1. Для регрессионной модели зависимости среднедушевого денежного дохода населения (руб., у ) от объема валового регионального продукта (тыс. р., х 1 ) и уровня безработицы в субъекте (%, х 2 ) получено уравнение . Величина коэффициента регрессии при переменной х 2 свидетельствует о том, что при изменении уровня безработицы на 1% среднедушевой денежный доход ______ рубля при неизменной величине валового регионального продукта.
изменится на (-1,67)
2. В уравнении линейной множественной регрессии:
![]() , где – стоимость основных фондов (тыс. руб.); – численность занятых (тыс. чел.); y
– объем промышленного производства (тыс. руб.) параметр при переменной х 1
, равный 10,8, означает, что при увеличении объема основных фондов на _____ объем промышленного производства _____ при постоянной численности занятых.
, где – стоимость основных фондов (тыс. руб.); – численность занятых (тыс. чел.); y
– объем промышленного производства (тыс. руб.) параметр при переменной х 1
, равный 10,8, означает, что при увеличении объема основных фондов на _____ объем промышленного производства _____ при постоянной численности занятых.
на 1 тыс. руб. … увеличится на 10,8 тыс. руб.
3. Известно, что доля остаточной дисперсии зависимой переменной в ее общей дисперсии равна 0,2. Тогда значение коэффициента детерминации составляет … 0,8
4. Построена эконометрическая модель для зависимости прибыли от реализации единицы продукции (руб., у ) от величины оборотных средств предприятия (тыс. р., х 1 ): . Следовательно, средний размер прибыли от реализации, не зависящий от объема оборотных средств предприятия, составляет _____ рубля. 10,75
5. F-статистика рассчитывается как отношение ______ дисперсии к ________ дисперсии, рассчитанных на одну степень свободы. факторной … остаточной
1. Для эконометрической модели уравнения регрессии ошибка модели определяется как ______ между фактическим значением зависимой переменной и ее расчетным значением. Разность
2. Величина называется … случайной составляющей
3. В эконометрической модели уравнения регрессии величина отклонения фактического значения зависимой переменной от ее расчетного значения характеризует … ошибку модели
4. Известно, что доля объясненной дисперсии в общей дисперсии равна 0,2. Тогда значение коэффициента детерминации составляет … 0,2
5. При методе наименьших квадратов параметры уравнения парной линейной регрессии ![]() определяются из условия ______ остатков .
минимизации суммы квадратов
определяются из условия ______ остатков .
минимизации суммы квадратов
1. Для обнаружения автокорреляции в остатках используется …
статистика Дарбина – Уотсона
2. Известно, что коэффициент автокорреляции остатков первого порядка равен –0,3. Также даны критические значения статистики Дарбина – Уотсона для заданного количества параметров при неизвестном и количестве наблюдений , . По данным характеристикам можно сделать вывод о том, что …автокорреляция остатков отсутствует
1. ПОСТРОИМ МАТРИЦУ КОЭФФИЦИЕНТОВ ПАРНОЙ КОРРЕЛЯЦИИ.
Для этого рассчитаем коэффициенты парной корреляции по формуле:
Необходимые расчеты представлены в таблице 9.
![]() -
-
связь между выручкой предприятия Y и объемом капиталовложений Х 1 слабая и прямая;
![]() -
-
связи между выручкой предприятия Y и основными производственными фондами Х 2 практически нет;
![]() -
-
связь между объемом капиталовложений Х 1 и основными производственными фондами Х 2 тесная и прямая;
Таблица 9
Вспомогательная таблица для расчета коэффициентов парных корреляций
| t | Y | X1 | X2 | (y-yср)* | (y-yср)* | (х1-х1ср)* |
|||
| 1998 | 3,0 | 1,1 | 0,4 | 0,0196 | 0,0484 | 0,0841 | 0,0308 | 0,0406 | 0,0638 |
| 1999 | 2,9 | 1,1 | 0,4 | 0,0576 | 0,0484 | 0,0841 | 0,0528 | 0,0696 | 0,0638 |
| 2000 | 3,0 | 1,2 | 0,7 | 0,0196 | 0,0144 | 1E-04 | 0,0168 | -0,0014 | -0,0012 |
| 2001 | 3,1 | 1,4 | 0,9 | 0,0016 | 0,0064 | 0,0441 | -0,0032 | -0,0084 | 0,0168 |
| 2002 | 3,2 | 1,4 | 0,9 | 0,0036 | 0,0064 | 0,0441 | 0,0048 | 0,0126 | 0,0168 |
| 2003 | 2,8 | 1,4 | 0,8 | 0,1156 | 0,0064 | 0,0121 | -0,0272 | -0,0374 | 0,0088 |
| 2004 | 2,9 | 1,3 | 0,8 | 0,0576 | 0,0004 | 0,0121 | 0,0048 | -0,0264 | -0,0022 |
| 2005 | 3,4 | 1,6 | 1,1 | 0,0676 | 0,0784 | 0,1681 | 0,0728 | 0,1066 | 0,1148 |
| 2006 | 3,5 | 1,3 | 0,4 | 0,1296 | 0,0004 | 0,0841 | -0,0072 | -0,1044 | 0,0058 |
| 2007 | 3,6 | 1,4 | 0,5 | 0,2116 | 0,0064 | 0,0361 | 0,0368 | -0,0874 | -0,0152 |
| Σ | 31,4 | 13,2 | 6,9 | 0,684 | 0,216 | 0,569 | 0,182 | -0,036 | 0,272 |
| Средн. | 3,14 | 1,32 | 0,69 |
Также матрицу коэффициентов парных корреляций можно найти в среде Excel с помощью надстройки АНАЛИЗ ДАННЫХ, инструмента КОРРЕЛЯЦИЯ.
Матрица коэффициентов парной корреляции имеет вид:
| Y | X1 | X2 | |
| Y | 1 | ||
| X1 | 0,4735 | 1 | |
| X2 | -0,0577 | 0,7759 | 1 |
Матрица парных коэффициентов корреляции показывает, что результативный признак у (выручка) имеет слабую связь с объемом капиталовложений х 1 , а с Размером ОПФ связи практически нет. Связь между факторами в модели оценивается как тесная, что говорит о их линейной зависимости, мультиколлинеарности.
2. ПОСТРОИТЬ ЛИНЕЙНУЮ МОДЕЛЬ МНОЖЕСТВЕННОЙ РЕГРЕССИИ ![]()
Параметры модели найдем с помощью МНК. Для этого составим систему нормальных уравнений.

Расчеты представлены в таблице 10.

Решим систему уравнений, используя метод Крамера:




![]()
![]()
![]()
Таблица 10
Вспомогательные вычисления для нахождения параметров линейной модели множественной регрессии
| y | |||||||
| 3,0 | 1,1 | 0,4 | 1,21 | 0,44 | 0,16 | 3,3 | 1,2 |
| 2,9 | 1,1 | 0,4 | 1,21 | 0,44 | 0,16 | 3,19 | 1,16 |
| 3,0 | 1,2 | 0,7 | 1,44 | 0,84 | 0,49 | 3,6 | 2,1 |
| 3,1 | 1,4 | 0,9 | 1,96 | 1,26 | 0,81 | 4,34 | 2,79 |
| 3,2 | 1,4 | 0,9 | 1,96 | 1,26 | 0,81 | 4,48 | 2,88 |
| 2,8 | 1,4 | 0,8 | 1,96 | 1,12 | 0,64 | 3,92 | 2,24 |
| 2,9 | 1,3 | 0,8 | 1,69 | 1,04 | 0,64 | 3,77 | 2,32 |
| 3,4 | 1,6 | 1,1 | 2,56 | 1,76 | 1,21 | 5,44 | 3,74 |
| 3,5 | 1,3 | 0,4 | 1,69 | 0,52 | 0,16 | 4,55 | 1,4 |
| 3,6 | 1,4 | 0,5 | 1,96 | 0,7 | 0,25 | 5,04 | 1,8 |
| 31,4 | 13,2 | 6,9 | 17,64 | 9,38 | 5,33 | 41,63 | 21,63 |
Линейная модель множественной регрессии имеет вид:
Если объем капиталовложений увеличить на 1 млн. руб., то выручка предприятия увеличиться в среднем на 2,317 млн. руб. при неизменных размерах основных производственных фондов.
Если основные производственные фонды увеличить на 1 млн. руб., то выручка предприятия уменьшиться в среднем на 1,171 млн. руб. при неизменном объеме капиталовложений.
3. РАССЧИТАЕМ:
коэффициент детерминации:
67,82% изменения выручки предприятия обусловлено изменением объема капиталовложений и основных производственных фондов, на 32,18% - влиянием факторов, не включенных в модель.
F – критерий Фишера
Проверим значимость уравнения
Табличное значение F – критерия при уровне значимости α = 0,05 и числе степеней свободы d.f. 1 = k = 2 (количество факторов), числе степеней свободы d.f. 2 = (n – k – 1) = (10 – 2 – 1) = 7 составит 4,74.
Так как F расч. = 7,375 > F табл. = 4.74, то уравнение регрессии в целом можно считать статистически значимым.
Рассчитанные показатели можно найти в среде Excel с помощью надстройки АНАЛИЗА ДАННЫХ, инструмента РЕГРЕССИЯ.
Таблица 11
Вспомогательные вычисления для нахождения средней относительной ошибки аппроксимации
| y | А | ||||
| 3,0 | 1,1 | 0,4 | 2,97 | 0,03 | 0,010 |
| 2,9 | 1,1 | 0,4 | 2,97 | -0,07 | 0,024 |
| 3,0 | 1,2 | 0,7 | 2,85 | 0,15 | 0,050 |
| 3,1 | 1,4 | 0,9 | 3,08 | 0,02 | 0,007 |
| 3,2 | 1,4 | 0,9 | 3,08 | 0,12 | 0,038 |
| 2,8 | 1,4 | 0,8 | 3,20 | -0,40 | 0,142 |
| 2,9 | 1,3 | 0,8 | 2,96 | -0,06 | 0,022 |
| 3,4 | 1,6 | 1,1 | 3,31 | 0,09 | 0,027 |
| 3,5 | 1,3 | 0,4 | 3,43 | 0,07 | 0,019 |
| 3,6 | 1,4 | 0,5 | 3,55 | 0,05 | 0,014 |
| 0,353 |
среднюю относительную ошибку аппроксимации
В среднем расчетные значения отличаются от фактических на 3,53 %. Ошибка небольшая, модель можно считать точной.
4. Построить степенную модель множественной регрессии ![]()
Для построения данной модели прологарифмируем обе части равенства
lg y = lg a + β 1 ∙ lg x 1 + β 2 ∙ lg x 2 .
Сделаем замену Y = lg y, A = lg a, X 1 = lg x 1 , X 2 = lg x 2 .
Тогда Y = A + β 1 ∙ X 1 + β 2 ∙ X 2 – линейная двухфакторная модель регрессии. Можно применить МНК.

Расчеты представлены в таблице 12.

Таблица 12
Вспомогательные вычисления для нахождения параметров степенной модели множественной регрессии
| y | lg y | |||||||||
| 3,0 | 1,1 | 0,4 | 0,041 | -0,398 | 0,477 | 0,002 | -0,016 | 0,020 | 0,158 | -0,190 |
| 2,9 | 1,1 | 0,4 | 0,041 | -0,398 | 0,462 | 0,002 | -0,016 | 0,019 | 0,158 | -0,184 |
| 3,0 | 1,2 | 0,7 | 0,079 | -0,155 | 0,477 | 0,006 | -0,012 | 0,038 | 0,024 | -0,074 |
| 3,1 | 1,4 | 0,9 | 0,146 | -0,046 | 0,491 | 0,021 | -0,007 | 0,072 | 0,002 | -0,022 |
| 3,2 | 1,4 | 0,9 | 0,146 | -0,046 | 0,505 | 0,021 | -0,007 | 0,074 | 0,002 | -0,023 |
| 2,8 | 1,4 | 0,8 | 0,146 | -0,097 | 0,447 | 0,021 | -0,014 | 0,065 | 0,009 | -0,043 |
| 2,9 | 1,3 | 0,8 | 0,114 | -0,097 | 0,462 | 0,013 | -0,011 | 0,053 | 0,009 | -0,045 |
| 3,4 | 1,6 | 1,1 | 0,204 | 0,041 | 0,531 | 0,042 | 0,008 | 0,108 | 0,002 | 0,022 |
| 3,5 | 1,3 | 0,4 | 0,114 | -0,398 | 0,544 | 0,013 | -0,045 | 0,062 | 0,158 | -0,217 |
| 3,6 | 1,4 | 0,5 | 0,146 | -0,301 | 0,556 | 0,021 | -0,044 | 0,081 | 0,091 | -0,167 |
| 31,4 | 13,2 | 6,9 | 1,178 | -1,894 | 4,955 | 0,163 | -0,165 | 0,592 | 0,614 | -0,943 |
Решаем систему уравнений применяя метод Крамера.




![]()
![]()
Степенная модель множественной регрессии имеет вид:
![]()
В степенной функции коэффициенты при факторах являются коэффициентами эластичности. Коэффициент эластичности показывает на сколько процентов измениться в среднем значение результативного признака у, если один из факторов увеличить на 1 % при неизменном значении других факторов.
Если объем капиталовложений увеличить на 1%, то выручка предприятия увеличиться в среднем на 0,897% при неизменных размерах основных производственных фондов.
Если основные производственные фонды увеличить на 1%, то выручка предприятия уменьшиться на 0,226% при неизменных капиталовложениях.
5. РАССЧИТАЕМ:
коэффициент множественной корреляции:

Связь выручки предприятия с объемом капиталовложений и основными производственными фондами тесная.
Таблица 13
Вспомогательные вычисления для нахождения коэффициента множественной корреляции, коэффициента детерминации, ср.относ.ошибки аппроксимации степенной модели множественной регрессии
| Y | (Y-Y расч.) 2 | A | ||||
| 3,0 | 1,1 | 0,4 | 2,978 | 0,000 | 0,020 | 0,007 |
| 2,9 | 1,1 | 0,4 | 2,978 | 0,006 | 0,058 | 0,027 |
| 3,0 | 1,2 | 0,7 | 2,838 | 0,026 | 0,020 | 0,054 |
| 3,1 | 1,4 | 0,9 | 3,079 | 0,000 | 0,002 | 0,007 |
| 3,2 | 1,4 | 0,9 | 3,079 | 0,015 | 0,004 | 0,038 |
| 2,8 | 1,4 | 0,8 | 3,162 | 0,131 | 0,116 | 0,129 |
| 2,9 | 1,3 | 0,8 | 2,959 | 0,003 | 0,058 | 0,020 |
| 3,4 | 1,6 | 1,1 | 3,317 | 0,007 | 0,068 | 0,024 |
| 3,5 | 1,3 | 0,4 | 3,460 | 0,002 | 0,130 | 0,012 |
| 3,6 | 1,4 | 0,5 | 3,516 | 0,007 | 0,212 | 0,023 |
| 31,4 | 13,2 | 6,9 | 0,198 | 0,684 | 0,342 |
коэффициент детерминации:
71,06% изменения выручки предприятия в степенной модели обусловлено изменением объема капиталовложений и основных производственных фондов, на 28,94 % - влиянием факторов, не включенных в модель.
F – критерий Фишера
Проверим значимость уравнения
Табличное значение F – критерия при уровне значимости α = 0,05 и числе степеней свободы d.f. 1 = k = 2, числе степеней свободы d.f. 2 = (n – k – 1) = (10 – 2 – 1) = 7 составит 4,74.
Так как F расч. = 8,592 > F табл. = 4.74, то уравнение степенной регрессии в целом можно считать статистически значимым.
Посадка невозможна, в каком из реализуемых случаев расход топлива меньше. Получить программу оптимального управления, когда до некоторого момента t1 управление отсутствует u*=0, а начиная с t=t1, управление равно своему максимальному значению u*=umax, что соответствует минимальному расходу топлива. 6.) Решить каноническую систему уравнений, рассматривая ее для случаев, когда и управление...
К составлению математических моделей. Если математическая модель - это диагноз заболевания, то алгоритм - это метод лечения. Можно выделить следующие основные этапы операционного исследования: наблюдение явления и сбор исходных данных; постановка задачи; построение математической модели; расчет модели; тестирование модели и анализ выходных данных. Если полученные результаты не удовлетворяют...
Математических построений по аналогии с выявляет в плоском приближении продольно-скалярную электромагнитную волну с электрической - (28) и магнитной (29) синфазными составляющими. Математическая модель безвихревой электродинамики характеризуется скалярно-векторной структурой своих уравнений. Основополагающие уравнения безвихревой электродинамики сведены в таблице 1. Таблица 1 , ...
Для определения степени зависимости между несколькими показателями применяется множественные коэффициенты корреляции. Их затем сводят в отдельную таблицу, которая имеет название корреляционной матрицы. Наименованиями строк и столбцов такой матрицы являются названия параметров, зависимость которых друг от друга устанавливается. На пересечении строк и столбцов располагаются соответствующие коэффициенты корреляции. Давайте выясним, как можно провести подобный расчет с помощью инструментов Excel.
Принято следующим образом определять уровень взаимосвязи между различными показателями, в зависимости от коэффициента корреляции:
- 0 – 0,3 – связь отсутствует;
- 0,3 – 0,5 – связь слабая;
- 0,5 – 0,7 – средняя связь;
- 0,7 – 0,9 – высокая;
- 0,9 – 1 – очень сильная.
Если корреляционный коэффициент отрицательный, то это значит, что связь параметров обратная.
Для того, чтобы составить корреляционную матрицу в Экселе, используется один инструмент, входящий в пакет «Анализ данных» . Он так и называется – «Корреляция» . Давайте узнаем, как с помощью него можно вычислить показатели множественной корреляции.
Этап 1: активация пакета анализа
Сразу нужно сказать, что по умолчанию пакет «Анализ данных» отключен. Поэтому, прежде чем приступить к процедуре непосредственного вычисления коэффициентов корреляции, нужно его активировать. К сожалению, далеко не каждый пользователь знает, как это делать. Поэтому мы остановимся на данном вопросе.


После указанного действия пакет инструментов «Анализ данных» будет активирован.
Этап 2: расчет коэффициента
Теперь можно переходить непосредственно к расчету множественного коэффициента корреляции. Давайте на примере представленной ниже таблицы показателей производительности труда, фондовооруженности и энерговооруженности на различных предприятиях рассчитаем множественный коэффициент корреляции указанных факторов.


Этап 3: анализ полученного результата
Теперь давайте разберемся, как понимать тот результат, который мы получили в процессе обработки данных инструментом «Корреляция» в программе Excel.
Как видим из таблицы, коэффициент корреляции фондовооруженности (Столбец 2 ) и энерговооруженности (Столбец 1 ) составляет 0,92, что соответствует очень сильной взаимосвязи. Между производительностью труда (Столбец 3 ) и энерговооруженностью (Столбец 1 ) данный показатель равен 0,72, что является высокой степенью зависимости. Коэффициент корреляции между производительностью труда (Столбец 3 ) и фондовооруженностью (Столбец 2 ) равен 0,88, что тоже соответствует высокой степени зависимости. Таким образом, можно сказать, что зависимость между всеми изучаемыми факторами прослеживается довольно сильная.
Как видим, пакет «Анализ данных» в Экселе представляет собой очень удобный и довольно легкий в обращении инструмент для определения множественного коэффициента корреляции. С его же помощью можно производить расчет и обычной корреляции между двумя факторами.
Коэффициент корреляции отражает степень взаимосвязи между двумя показателями. Всегда принимает значение от -1 до 1. Если коэффициент расположился около 0, то говорят об отсутствии связи между переменными.
Если значение близко к единице (от 0,9, например), то между наблюдаемыми объектами существует сильная прямая взаимосвязь. Если коэффициент близок к другой крайней точке диапазона (-1), то между переменными имеется сильная обратная взаимосвязь. Когда значение находится где-то посередине от 0 до 1 или от 0 до -1, то речь идет о слабой связи (прямой или обратной). Такую взаимосвязь обычно не учитывают: считается, что ее нет.
Расчет коэффициента корреляции в Excel
Рассмотрим на примере способы расчета коэффициента корреляции, особенности прямой и обратной взаимосвязи между переменными.
Значения показателей x и y:
Y – независимая переменная, x – зависимая. Необходимо найти силу (сильная / слабая) и направление (прямая / обратная) связи между ними. Формула коэффициента корреляции выглядит так:

Чтобы упростить ее понимание, разобьем на несколько несложных элементов.


Между переменными определяется сильная прямая связь.
Встроенная функция КОРРЕЛ позволяет избежать сложных расчетов. Рассчитаем коэффициент парной корреляции в Excel с ее помощью. Вызываем мастер функций. Находим нужную. Аргументы функции – массив значений y и массив значений х:

Покажем значения переменных на графике:

Видна сильная связь между y и х, т.к. линии идут практически параллельно друг другу. Взаимосвязь прямая: растет y – растет х, уменьшается y – уменьшается х.
Матрица парных коэффициентов корреляции в Excel
Корреляционная матрица представляет собой таблицу, на пересечении строк и столбцов которой находятся коэффициенты корреляции между соответствующими значениями. Имеет смысл ее строить для нескольких переменных.

Матрица коэффициентов корреляции в Excel строится с помощью инструмента «Корреляция» из пакета «Анализ данных».


Между значениями y и х1 обнаружена сильная прямая взаимосвязь. Между х1 и х2 имеется сильная обратная связь. Связь со значениями в столбце х3 практически отсутствует.
Анализ матрицы парных коэффициентов корреляции показывает, что результативный показатель наиболее тесно связан с показателем x (4) - количество удобрений, расходуемых на 1 га ().
В то же время
связь между признаками-аргументами
достаточно тесная. Так, существует
практически функциональная связь между
числом колесных тракторов (x
(1))
и числом орудий поверхностной обработки
почвы .
.
О наличии
мультиколлинеарности свидетельствуют
также коэффициенты корреляции
 и
и .
Учитывая тесную взаимосвязь показателейx
(1) , x
(2) и x
(3) ,
в регрессионную модель урожайности
может войти лишь один из них.
.
Учитывая тесную взаимосвязь показателейx
(1) , x
(2) и x
(3) ,
в регрессионную модель урожайности
может войти лишь один из них.
Чтобы продемонстрировать отрицательное влияние мультиколлинеарности, рассмотрим регрессионную модель урожайности, включив в нее все исходные показатели:

 F набл
= 121.
F набл
= 121.
В скобках
указаны значения исправленных оценок
среднеквадратических отклонений оценок
коэффициентов уравнения
 .
.
Под уравнением
регрессии представлены следующие его
параметры адекватности: множественный
коэффициент детерминации
 ;
исправленная оценка остаточной дисперсии
;
исправленная оценка остаточной дисперсии ,
средняя относительная ошибка аппроксимациии расчетное значение-критерия
F набл = 121.
,
средняя относительная ошибка аппроксимациии расчетное значение-критерия
F набл = 121.
Уравнение регрессии значимо, т.к. F набл = 121 > F kp = 2,85 найденного по таблицеF -распределения при=0,05; 1 =6 и 2 =14.
Из этого следует, что 0, т.е. и хотя бы один из коэффициентов уравнения j (j = 0, 1, 2, ..., 5) не равен нулю.
Для проверки
гипотезы о значимости отдельных
коэффициентов регрессии H0: j =0,
гдеj
=1,2,3,4,5, сравнивают критическое
значениеt
kp = 2,14, найденное по
таблицеt
-распределения при уровне
значимости=2Q
=0,05
и числе степеней свободы=14,
с расчетным значением .
Из уравнения следует, что статистически
значимым является коэффициент регрессии
только при x
(4) , так какt
4 =2,90
>t
kp =2,14.
.
Из уравнения следует, что статистически
значимым является коэффициент регрессии
только при x
(4) , так какt
4 =2,90
>t
kp =2,14.
Не поддаются экономической интерпретации отрицательные знаки коэффициентов регрессии при x (1) и x (5) . Из отрицательных значений коэффициентов следует, что повышение насыщенности сельского хозяйства колесными тракторами (x (1)) и средствами оздоровления растений (x (5)) отрицательно сказывается на урожайности. Таким образом, полученное уравнение регрессии неприемлемо.
Для получения уравнения регрессии со значимыми коэффициентами используем пошаговый алгоритм регрессионного анализа. Первоначально используем пошаговый алгоритм с исключением переменных.
Исключим из модели переменную x (1) , которой соответствует минимальное по абсолютной величине значениеt 1 =0,01. Для оставшихся переменных вновь построим уравнение регрессии:
Полученное уравнение значимо, т.к. F набл = 155 > F kp = 2,90, найденного при уровне значимости=0,05 и числах степеней свободы 1 =5 и 2 =15 по таблицеF -распределения, т.е. вектор0. Однако в уравнении значим только коэффициент регрессии приx (4) . Расчетные значенияt j для остальных коэффициентов меньшеt кр = 2,131, найденного по таблицеt -распределения при=2Q =0,05 и=15.
Исключив из модели переменную x (3) , которой соответствует минимальное значениеt 3 =0,35 и получим уравнение регрессии:
 (2.9)
(2.9)
В полученном уравнении статистически не значим и экономически не интерпретируем коэффициент при x (5) . Исключивx (5) получим уравнение регрессии:
 (2.10)
(2.10)
Мы получили значимое уравнение регрессии со значимыми и интерпретируемыми коэффициентами.
Однако полученное уравнение является не единственно “хорошей” и не “самой лучшей” моделью урожайности в нашем примере.
Покажем, что в условии мультиколлинеарности пошаговый алгоритм с включением переменных является более эффективным. На первом шаге в модель урожайностиy входит переменная x (4) , имеющая самый высокий коэффициент корреляции сy , объясняемой переменнойr (y , x (4))=0,58. На втором шаге, включая уравнение наряду сx (4) переменныеx (1) илиx (3) , мы получим модели, которые по экономическим соображениям и статистическим характеристикам превосходят (2.10):
 (2.11)
(2.11)
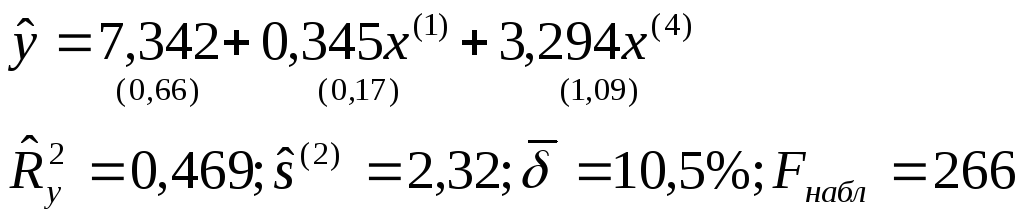 (2.12)
(2.12)
Включение в уравнение любой из трех оставшихся переменных ухудшает его свойства. Смотри, например, уравнение (2.9).
Таким образом, мы имеем три “хороших” модели урожайности, из которых нужно выбрать по экономическим и статистическим соображениям одну.
По статистическим
критериям наиболее адекватна модель
(2.11). Ей соответствуют минимальные
значения остаточной дисперсии
 =2,26
и средней относительной ошибки
аппроксимациии наибольшие значения
=2,26
и средней относительной ошибки
аппроксимациии наибольшие значения и F набл = 273.
и F набл = 273.
Несколько худшие показатели адекватности имеет модель (2.12), а затем - модель (2.10).
Будем теперь выбирать наилучшую из моделей (2.11) и (2.12). Эти модели отличаются друг от друга переменными x (1) иx (3) . Однако в моделях урожайностей переменнаяx (1) (число колесных тракторов на 100 га) более предпочтительна, чем переменнаяx (3) (число орудий поверхностной обработки почвы на 100 га), которая является в некоторой степени вторичной (или производной от x (1)).
В этой связи из экономических соображений предпочтение следует отдать модели (2.12). Таким образом, после реализации алгоритма пошагового регрессионного анализа с включением переменных и учета того, что в уравнение должна войти только одна из трех связанных переменных (x (1) ,x (2) илиx (3)) выбираем окончательное уравнение регрессии:

Уравнение
значимо при =0,05,
т.к. F набл = 266 > F kp = 3,20,
найденного по таблицеF
-распределения
при=Q
=0,05; 1 =3
и 2 =17. Значимы
и все коэффициенты регрессии и
и в уравненииt
j >t
kp (=2Q
=0,05;=17)=2,11. Коэффициент
регрессии 1 следует признать значимым ( 1 0)
из экономических соображений, при этомt
1 =2,09 лишь незначительно меньшеt
kp = 2,11.
в уравненииt
j >t
kp (=2Q
=0,05;=17)=2,11. Коэффициент
регрессии 1 следует признать значимым ( 1 0)
из экономических соображений, при этомt
1 =2,09 лишь незначительно меньшеt
kp = 2,11.
Из уравнения регрессии следует, что увеличение на единицу числа тракторов на 100 га пашни (при фиксированном значении x (4)) приводит к росту урожайности зерновых в среднем на 0,345 ц/га.
Приближенный расчет коэффициентов эластичности э 1 0,068 и э 2 0,161 показывает, что при увеличении показателейx (1) иx (4) на 1% урожайность зерновых повышается в среднем соответственно на 0,068% и 0,161%.
Множественный
коэффициент детерминации
 свидетельствует о том, что только 46,9%
вариации урожайности объясняется
вошедшими в модель показателями (x
(1) иx
(4)), то есть насыщенностью
растениеводства тракторами и удобрениями.
Остальная часть вариации обусловлена
действием неучтенных факторов (x
(2) ,x
(3) ,x
(5) , погодные
условия и др.). Средняя относительная
ошибка аппроксимациихарактеризует адекватность модели, так
же как и величина остаточной дисперсии
свидетельствует о том, что только 46,9%
вариации урожайности объясняется
вошедшими в модель показателями (x
(1) иx
(4)), то есть насыщенностью
растениеводства тракторами и удобрениями.
Остальная часть вариации обусловлена
действием неучтенных факторов (x
(2) ,x
(3) ,x
(5) , погодные
условия и др.). Средняя относительная
ошибка аппроксимациихарактеризует адекватность модели, так
же как и величина остаточной дисперсии .
При интерпретации уравнения регрессии
интерес представляют значения
относительных ошибок аппроксимации
.
При интерпретации уравнения регрессии
интерес представляют значения
относительных ошибок аппроксимации .
Напомним, что
.
Напомним, что -
модельное значение результативного
показателя, характеризует среднее для
совокупности рассматриваемых районов
значение урожайности при условии, что
значения объясняющих переменныхx
(1) иx
(4) зафиксированы на одном
и том же уровне, а именноx
(1) =x
i
(1) иx
(4)
= x
i
(4) . Тогда по значениям i
можно
сопоставлять районы по урожайности.
Районы, которым соответствуют значения i
>0, имеют
урожайность выше среднего, а i
<0
- ниже среднего.
-
модельное значение результативного
показателя, характеризует среднее для
совокупности рассматриваемых районов
значение урожайности при условии, что
значения объясняющих переменныхx
(1) иx
(4) зафиксированы на одном
и том же уровне, а именноx
(1) =x
i
(1) иx
(4)
= x
i
(4) . Тогда по значениям i
можно
сопоставлять районы по урожайности.
Районы, которым соответствуют значения i
>0, имеют
урожайность выше среднего, а i
<0
- ниже среднего.
В нашем примере, по урожайности наиболее эффективно растениеводство ведется в районе, которому соответствует 7 =28%, где урожайность на 28% выше средней по региону, и наименее эффективно - в районе с 20 =27,3%.


