Экономический смысл коэффициентов регрессии. Уравнение регрессии
1. Построим уравнения степенной нелинейной регрессии вида для пар переменных y, x.
Нахождение модели парной регрессии сводится к оценке уравнения в целом и по параметрам (b0, b1). Для оценки параметров однофакторной модели используют метод наименьших квадратов (МНК). В МНК получается, что сумма квадратов отклонений фактических значений показателя у от теоретических ух минимальна
Сущность нелинейных уравнений заключается в приведении их к линейному виду и как при линейных уравнениях решается система относительно коэффициентов b0 и b1.


Рисунок 3 Линия регрессии на корреляционном поле. Ось ординат - значения y(Производительность труда), ось абсцисс -значения x (Удельный вес рабочих в составе ППП)

Рисунок 4 Линия регрессии на корреляционном поле. Ось ординат - значения y(степ.функция), ось абсцисс -значения x (Удельный вес рабочих в составе ППП)
Найдем среднюю относительную ошибку аппроксимации по формуле:

Полученное значение между 20% и 50%, что свидетельствует о существенности удовлетворительного отклонения расчетных данных от фактических, по которым построена эконометрическая модель.
Исследование статистической значимости уравнения регрессии в целом проводится с помощью F-критерия Фишера. Расчетное значение критерия находится по формуле:

Для парного уравнения p = 1.
Табличное (теоретическое) значение критерия находится по таблице критических значений распределения Фишера-Снедекора по уровню значимости по уровню значимости б и двум числам степеней свободы k1 = p = 1 и k2 = n - p - 1 = 51.
Если Fрасч то гипотеза принимается, а уравнение линейной регрессии в целом считается статистически незначимым (с вероятностью ошибки 5%).Для уравнения Fрасч = 0,01609). Неравенство выполняется. Уравнение в целом статистически незначимо. Теснота нелинейной корреляционной связи определяется с помощью корреляционных отношений (индекс корреляции). Регрессионный анализ — это статистический метод исследования, позволяющий показать зависимость того или иного параметра от одной либо нескольких независимых переменных. В докомпьютерную эру его применение было достаточно затруднительно, особенно если речь шла о больших объемах данных. Сегодня, узнав как построить регрессию в Excel, можно решать сложные статистические задачи буквально за пару минут. Ниже представлены конкретные примеры из области экономики. Само это понятие было введено в математику в 1886 году. Регрессия бывает: Рассмотрим задачу определения зависимости количества уволившихся членов коллектива от средней зарплаты на 6 промышленных предприятиях. Задача. На шести предприятиях проанализировали среднемесячную заработную плату и количество сотрудников, которые уволились по собственному желанию. В табличной форме имеем: Количество уволившихся Зарплата 30000 рублей 35000 рублей 40000 рублей 45000 рублей 50000 рублей 55000 рублей 60000 рублей Для задачи определения зависимости количества уволившихся работников от средней зарплаты на 6 предприятиях модель регрессии имеет вид уравнения Y = а 0 + а 1 x 1 +…+а k x k , где х i — влияющие переменные, a i — коэффициенты регрессии, a k — число факторов. Для данной задачи Y — это показатель уволившихся сотрудников, а влияющий фактор — зарплата, которую обозначаем X. Анализу регрессии в Excel должно предшествовать применение к имеющимся табличным данным встроенных функций. Однако для этих целей лучше воспользоваться очень полезной надстройкой «Пакет анализа». Для его активации нужно: Если все сделано правильно, в правой части вкладки «Данные», расположенном над рабочим листом «Эксель», появится нужная кнопка. Теперь, когда под рукой есть все необходимые виртуальные инструменты для осуществления эконометрических расчетов, можем приступить к решению нашей задачи. Для этого: В результате программа автоматически заполнит новый лист табличного процессора данными анализа регрессии. Обратите внимание! В Excel есть возможность самостоятельно задать место, которое вы предпочитаете для этой цели. Например, это может быть тот же лист, где находятся значения Y и X, или даже новая книга, специально предназначенная для хранения подобных данных. В Excel данные полученные в ходе обработки данных рассматриваемого примера имеют вид: Прежде всего, следует обратить внимание на значение R-квадрата. Он представляет собой коэффициент детерминации. В данном примере R-квадрат = 0,755 (75,5%), т. е. расчетные параметры модели объясняют зависимость между рассматриваемыми параметрами на 75,5 %. Чем выше значение коэффициента детерминации, тем выбранная модель считается более применимой для конкретной задачи. Считается, что она корректно описывает реальную ситуацию при значении R-квадрата выше 0,8. Если R-квадрата<0,5, то такой анализа регрессии в Excel нельзя считать резонным. Число 64,1428 показывает, каким будет значение Y, если все переменные xi в рассматриваемой нами модели обнулятся. Иными словами можно утверждать, что на значение анализируемого параметра оказывают влияние и другие факторы, не описанные в конкретной модели. Следующий коэффициент -0,16285, расположенный в ячейке B18, показывает весомость влияния переменной Х на Y. Это значит, что среднемесячная зарплата сотрудников в пределах рассматриваемой модели влияет на число уволившихся с весом -0,16285, т. е. степень ее влияния совсем небольшая. Знак «-» указывает на то, что коэффициент имеет отрицательное значение. Это очевидно, так как всем известно, что чем больше зарплата на предприятии, тем меньше людей выражают желание расторгнуть трудовой договор или увольняется. Под таким термином понимается уравнение связи с несколькими независимыми переменными вида: y=f(x 1 +x 2 +…x m) + ε, где y — это результативный признак (зависимая переменная), а x 1 , x 2 , …x m — это признаки-факторы (независимые переменные). Для множественной регрессии (МР) ее осуществляют, используя метод наименьших квадратов (МНК). Для линейных уравнений вида Y = a + b 1 x 1 +…+b m x m + ε строим систему нормальных уравнений (см. ниже) Чтобы понять принцип метода, рассмотрим двухфакторный случай. Тогда имеем ситуацию, описываемую формулой Отсюда получаем: где σ — это дисперсия соответствующего признака, отраженного в индексе. МНК применим к уравнению МР в стандартизируемом масштабе. В таком случае получаем уравнение: в котором t y , t x 1, … t xm — стандартизируемые переменные, для которых средние значения равны 0; β i — стандартизированные коэффициенты регрессии, а среднеквадратическое отклонение — 1. Обратите внимание, что все β i в данном случае заданы, как нормируемые и централизируемые, поэтому их сравнение между собой считается корректным и допустимым. Кроме того, принято осуществлять отсев факторов, отбрасывая те из них, у которых наименьшие значения βi. Предположим, имеется таблица динамики цены конкретного товара N в течение последних 8 месяцев. Необходимо принять решение о целесообразности приобретения его партии по цене 1850 руб./т. номер месяца название месяца цена товара N 1750 рублей за тонну 1755 рублей за тонну 1767 рублей за тонну 1760 рублей за тонну 1770 рублей за тонну 1790 рублей за тонну 1810 рублей за тонну 1840 рублей за тонну Для решения этой задачи в табличном процессоре «Эксель» требуется задействовать уже известный по представленному выше примеру инструмент «Анализ данных». Далее выбирают раздел «Регрессия» и задают параметры. Нужно помнить, что в поле «Входной интервал Y» должен вводиться диапазон значений для зависимой переменной (в данном случае цены на товар в конкретные месяцы года), а в «Входной интервал X» — для независимой (номер месяца). Подтверждаем действия нажатием «Ok». На новом листе (если так было указано) получаем данные для регрессии. Строим по ним линейное уравнение вида y=ax+b, где в качестве параметров a и b выступают коэффициенты строки с наименованием номера месяца и коэффициенты и строки «Y-пересечение» из листа с результатами регрессионного анализа. Таким образом, линейное уравнение регрессии (УР) для задачи 3 записывается в виде: Цена на товар N = 11,714* номер месяца + 1727,54. или в алгебраических обозначениях y = 11,714 x + 1727,54 Чтобы решить, адекватно ли полученное уравнения линейной регрессии, используются коэффициенты множественной корреляции (КМК) и детерминации, а также критерий Фишера и критерий Стьюдента. В таблице «Эксель» с результатами регрессии они выступают под названиями множественный R, R-квадрат, F-статистика и t-статистика соответственно. КМК R дает возможность оценить тесноту вероятностной связи между независимой и зависимой переменными. Ее высокое значение свидетельствует о достаточно сильной связи между переменными «Номер месяца» и «Цена товара N в рублях за 1 тонну». Однако, характер этой связи остается неизвестным. Квадрат коэффициента детерминации R 2 (RI) представляет собой числовую характеристику доли общего разброса и показывает, разброс какой части экспериментальных данных, т.е. значений зависимой переменной соответствует уравнению линейной регрессии. В рассматриваемой задаче эта величина равна 84,8%, т. е. статистические данные с высокой степенью точности описываются полученным УР. F-статистика, называемая также критерием Фишера, используется для оценки значимости линейной зависимости, опровергая или подтверждая гипотезу о ее существовании. (критерий Стьюдента) помогает оценивать значимость коэффициента при неизвестной либо свободного члена линейной зависимости. Если значение t-критерия > t кр, то гипотеза о незначимости свободного члена линейного уравнения отвергается. В рассматриваемой задаче для свободного члена посредством инструментов «Эксель» было получено, что t=169,20903, а p=2,89Е-12, т. е. имеем нулевую вероятность того, что будет отвергнута верная гипотеза о незначимости свободного члена. Для коэффициента при неизвестной t=5,79405, а p=0,001158. Иными словами вероятность того, что будет отвергнута верная гипотеза о незначимости коэффициента при неизвестной, равна 0,12%. Таким образом, можно утверждать, что полученное уравнение линейной регрессии адекватно. Множественная регрессия в Excel выполняется с использованием все того же инструмента «Анализ данных». Рассмотрим конкретную прикладную задачу. Руководство компания «NNN» должно принять решение о целесообразности покупки 20 % пакета акций АО «MMM». Стоимость пакета (СП) составляет 70 млн американских долларов. Специалистами «NNN» собраны данные об аналогичных сделках. Было принято решение оценивать стоимость пакета акций по таким параметрам, выраженным в миллионах американских долларов, как: Кроме того, используется параметр задолженность предприятия по зарплате (V3 П) в тысячах американских долларов. Прежде всего, необходимо составить таблицу исходных данных. Она имеет следующий вид: Отмечают пункт «Новый рабочий лист» и нажимают «Ok». Получают анализ регрессии для данной задачи. «Собираем» из округленных данных, представленных выше на листе табличного процессора Excel, уравнение регрессии: СП = 0,103*СОФ + 0,541*VO - 0,031*VK +0,405*VD +0,691*VZP - 265,844. В более привычном математическом виде его можно записать, как: y = 0,103*x1 + 0,541*x2 - 0,031*x3 +0,405*x4 +0,691*x5 - 265,844 Данные для АО «MMM» представлены в таблице: Подставив их в уравнение регрессии, получают цифру в 64,72 млн американских долларов. Это значит, что акции АО «MMM» не стоит приобретать, так как их стоимость в 70 млн американских долларов достаточно завышена. Как видим, использование табличного процессора «Эксель» и уравнения регрессии позволило принять обоснованное решение относительно целесообразности вполне конкретной сделки. Теперь вы знаете, что такое регрессия. Примеры в Excel, рассмотренные выше, помогут вам в решение практических задач из области эконометрики. Инструкция
. Укажите количество исходных данных. Полученное решение сохраняется в файле Word
. Также автоматически создается шаблон решения в Excel
.
Уравнению регрессии первого порядка
- это уравнение парной линейной регрессии . Уравнение регрессии второго порядка
это полиномальное уравнение регрессии второго порядка: y = a + bx + cx 2 .
Уравнение регрессии третьего порядка
соответственно полиномальное уравнение регрессии третьего порядка: y = a + bx + cx 2 + dx 3 .
Чтобы привести нелинейные зависимости к линейной используют методы линеаризации (см. метод выравнивания): Решение. В калькуляторе последовательно выбираем виды нелинейной регрессии
. Получим таблицу следующего вида.
Степенное уравнение регрессии имеет вид y = a x b
Гиперболическое уравнение регрессии имеет вид y = b/x + a + ε
Логарифмическое уравнение регрессии имеет вид y = b ln(x) + a + ε
Показательное уравнение регрессии имеет вид y = a b x + ε
Многомерный
регрессионный анализ позволяет
разграничить влияние факторных признаков.
Параметр регрессии
при каждом факторном признаке Прогнозирование
на основе полученной модели
выполняется
аналогично прогнозам парной линейной
регрессии. Точечный
прогноз
получается при подстановке
прогнозных значений факторных признаков Интервальный
прогноз
указывает нижнюю и верхнюю
границу промежутка, в котором находится
истинное значение прогнозируемого
показателя т.е. истинное значение
прогнозируемого показателя
Пример 3.9.
По данным таблицы 3.17
записать уравнение регрессии и выполнить
анализ полученной модели. Решение.
Так как инструмент «Регрессия»
может выполнять только линейный
регрессионный анализ, то в итоге имеем
следующее уравнение многомерной
линейной регрессии Таблица
3.17. Результаты работы инструментаРегрессия
Выполним
анализ полученной модели регрессии: Следовательно,
модель регрессии пригодна для принятия
некоторых решений, но не для прогнозирования. Проанализируем наличие парной
корреляционной связи между факторными
признаками, входящими в модель регрессии,
по корреляционной матрице (рис.3.8): Рис.3.8.
Корреляционная матрица Обозначения
к корреляционной матрице:
Следовательно, на основе исследуемой
многомерной выборки можно сделать
вывод, что из рассматриваемых факторных
признаков на производительность труда
оказывают влияние трудоемкость единицы
продукции и премии. Эти факторные
признаки следует включить в модель
многомерной нелинейной регрессии. Так как коэффициент детерминации
сравнительно мал, то при разработке
модели регрессии следует рассмотреть
дополнительные неучтенные факторные
признаки. В
таблице 3.18 приведены результаты работы
инструмента «Регрессия» для модели
регрессии без факторного признака
Экономическая интерпретация коэффициентов регрессии в целом является завершающим этапом эконометрического моделирования на основе совокупности исходных данных. В данном случае экономическая интерпретация - это объяснение смысла, содержания полученных коэффициентов регрессии. На экономическую интерпретацию коэффициентов регрессии оказывают влияние такие факторы, как сфера экономики, для которой строится эконометрическая модель, количество исходных данных (объем совокупности) для анализа изучаемого явления и т.п. Одним из важнейших факторов интерпретации коэффициентов регрессии является вид полученной модели. Линейное уравнение регрессии
имеет вид y = bx + a + ε Здесь ε - случайная ошибка (отклонение, возмущение). Коэффициент множественной регрессии bj
показывает, на какую величину в среднем изменится результативный признак Y
, если переменную Xj
увеличить на единицу измерения, т. е. является нормативным коэффициентом. Параметр а = у, когда х = 0. Если х не может быть равен 0, то а не имеет экономического смысла. Интерпретировать можно только знак при а: если а > 0. то относительное изменение результата происходит медленнее, чем изменение фактора, т. е. вариация результата меньше вариации фактора: V < V. и наоборот. В линейной множественной регрессии коэффициенты при хi характеризуют среднее изменение результата с изменением соответствующего фактора на единицу при неизменных значениях других факторов, закреплённых на среднем уровне. При изучении вопросов потребления коэффициенты регрессии рассматриваются как характеристики предельной склонности к потреблению. Например, если функция потребления Сt имеет вид Сt = b0 + b1* Rt + b2* Rt-1 +epsilont, то потребление за t-й период времени зависит от дохода того же периода Rt и от дохода предшествующего периода Rt-1. Соответственно, коэффициент b1 характеризует эффект от единичного возрастания дохода Rt при неизменном уровне предыдущего дохода. Коэффициент b1 обычно называют краткосрочной предельной склонностью к потреблению. Общим эффектом возрастания как текущего, так и предыдущего дохода будет рост потребления на величину b = b1+b2. Коэффициент b рассматривается здесь как долгосрочная предельная склонность к потреблению. Уравнение парной степенной модели имеет вид: у = а х^b В уравнении парной степенной регрессии параметр b показывает: на сколько процентов изменится результативный показатель, при изменении фактора на /%, то есть является коэффициентом эластичности. Знак при коэффициенте регрессии указывает направление связи между фактором и результативным показателем: если Ь>0, следовательно, связь прямая и с увеличением значения фактора (х) возрастает и значение результативного показателя (у); если Ь<0, следовательно, связь обратная и с увеличением значения фактора (х) снижается значение результативного показателя.Таким образом, при увеличении расходов на конечное потребление на 1 %, в среднем доля расходов на питание снижается на 0,5. Таким образом, получили, что показатели степени при переменных в мультипликативной степенной модели являются соответствующими коэффициентами эластичности. Это важное свойство степенных моделей.Виды регрессии
Пример 1
Использование возможностей табличного процессора «Эксель»
в Excel
Анализ результатов регрессии для R-квадрата
Анализ коэффициентов
Множественная регрессия
Оценка параметров




Задача с использованием уравнения линейной регрессии
Анализ результатов
Задача о целесообразности покупки пакета акций
Решение средствами табличного процессора Excel


Изучение результатов и выводы
Ограничить однородную совокупность единиц, устранив аномальные объекты наблюдения можно через метод Ирвина или по правилу трех сигм (устранить те единицы, для которых значение объясняющего фактора отклоняется от среднего более, чем на утроенное среднеквадратичное отклонение).
Виды нелинейной регрессии
Здесь ε - случайная ошибка (отклонение, возмущение), отражающая влияние всех неучтенных факторов.

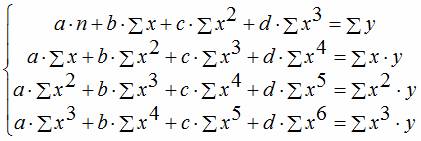
Пример
. По данным, взятым из соответствующей таблицы, выполнить следующие действия:
y = f(x)
Преобразование
Метод линеаризации
y = b x a
Y = ln(y); X = ln(x)
Логарифмирование
y = b e ax
Y = ln(y); X = x
Комбинированный
y = 1/(ax+b)
Y = 1/y; X = x
Замена переменных
y = x/(ax+b)
Y = x/y; X = x
Замена переменных. Пример
y = aln(x)+b
Y = y; X = ln(x)
Комбинированный
y = a + bx + cx 2
x 1 = x; x 2 = x 2
Замена переменных
y = a + bx + cx 2 + dx 3
x 1 = x; x 2 = x 2 ; x 3 = x 3
Замена переменных
y = a + b/x
x 1 = 1/x
Замена переменных
y = a + sqrt(x)b
x 1 = sqrt(x)
Замена переменных
Год
Фактическое конечное потребление домашних хозяйств (в текущих ценах), млрд. руб. (1995 г. - трлн. руб.), y
Среднедушевые денежные доходы населения (в месяц), руб. (1995 г. - тыс. руб.), х
1995
872
515,9
2000
3813
2281,1
2001
5014
3062
2002
6400
3947,2
2003
7708
5170,4
2004
9848
6410,3
2005
12455
8111,9
2006
15284
10196
2007
18928
12602,7
2008
23695
14940,6
2009
25151
16856,9
Экспоненциальное уравнение регрессии имеет вид y = a e bx
После линеаризации получим: ln(y) = ln(a) + bx
Получаем эмпирические коэффициенты регрессии: b = 0.000162, a = 7.8132
Уравнение регрессии: y = e 7.81321500 e 0.000162x = 2473.06858e 0.000162x
После линеаризации получим: ln(y) = ln(a) + b ln(x)
Эмпирические коэффициенты регрессии: b = 0.9626, a = 0.7714
Уравнение регрессии: y = e 0.77143204 x 0.9626 = 2.16286x 0.9626
После линеаризации получим: y=bx + a
Эмпирические коэффициенты регрессии: b = 21089190.1984, a = 4585.5706
Эмпирическое уравнение регрессии: y = 21089190.1984 / x + 4585.5706
Эмпирические коэффициенты регрессии: b = 7142.4505, a = -49694.9535
Уравнение регрессии: y = 7142.4505 ln(x) - 49694.9535
После линеаризации получим: ln(y) = ln(a) + x ln(b)
Эмпирические коэффициенты регрессии: b = 0.000162, a = 7.8132
y = e 7.8132 *e 0.000162x = 2473.06858*1.00016 xx
y
1/x
ln(x)
ln(y)
515.9
872
0.00194
6.25
6.77
2281.1
3813
0.000438
7.73
8.25
3062
5014
0.000327
8.03
8.52
3947.2
6400
0.000253
8.28
8.76
5170.4
7708
0.000193
8.55
8.95
6410.3
9848
0.000156
8.77
9.2
8111.9
12455
0.000123
9
9.43
10196
15284
9.8E-5
9.23
9.63
12602.7
18928
7.9E-5
9.44
9.85
14940.6
23695
6.7E-5
9.61
10.07
16856.9
25151
5.9E-5
9.73
10.13
 дает оценку его влияния на величину
результативного признака
дает оценку его влияния на величину
результативного признака в случае изменения
в случае изменения на единицу при постоянстве всех
остальных факторов.
на единицу при постоянстве всех
остальных факторов. в уравнение регрессии. Полученное
значение
в уравнение регрессии. Полученное
значение
 является
точечным прогнозом
результативного признака
является
точечным прогнозом
результативного признака .
. .
Доверительный интервал определяется
выражением
.
Доверительный интервал определяется
выражением с вероятностью 1 -принадлежит доверительному интервалу.
с вероятностью 1 -принадлежит доверительному интервалу.




 -
производительность труда (среднегодовая
выработка продукции на одного работника),
тыс. грн.;
-
производительность труда (среднегодовая
выработка продукции на одного работника),
тыс. грн.; -
трудоемкость единицы продукции;
-
трудоемкость единицы продукции; -
удельный вес рабочих в составе
промышленно-производственного персонала;
-
удельный вес рабочих в составе
промышленно-производственного персонала; -коэффициент
сменности оборудования;
-коэффициент
сменности оборудования; -
премии и вознаграждения на одного
работника, %;
-
премии и вознаграждения на одного
работника, %; -
непроизводственные расходы, %.
-
непроизводственные расходы, %. Выполните
анализ этой модели регрессии.
Выполните
анализ этой модели регрессии.


